喜讯丨我校多篇论文被顶级国际会议ICASSP录用


近日,2022年IEEE音频、语音与信号处理国际会议(2022 IEEE International Conference on Acoustics,Speech, and Signal Processing, ICASSP 2022)发布录用通知,我校蒙古文智能信息处理技术国家地方联合工程研究中心(蒙古文信息处理技术自治区重点实验室)有6篇论文被接收录用(包括合作),涉及智能语音交互领域的语音增强、语音鉴伪、语音识别等研究领域。ICASSP是由IEEE电气电子工程师学会主办的信号处理领域的顶级国际会议,是IEEE下语音方向最具代表性、最高荣誉的会议,在国际上享有盛誉并具有广泛的学术影响力。
工程研究中心高光来教授、张学良教授、飞龙教授带领团队多年来针对语音识别、语音合成、语音增强与分离等领域进行了深入的研究,提出了一系列创新性方法,在TASLP、ICASSP等语音信号处理领域国际顶级期刊和会议发表论文20多篇,并且研发的蒙古语语音识别、蒙古语语音合成和语音增强等智能系统已实际落地应用,对国家和自治区智能语音产业发展起到了积极推动作用。
在工程研究中心主任高光来教授的带领下,近几年团队规模和质量稳步提升,引进和培养了张怀文研究员(骏马计划B1岗)、刘瑞研究员(骏马计划B1岗)、张晖副教授等一批优秀的年轻教师,并成为了工程研究中心核心骨干力量。目前,工程研究中心专业技术人员29人,其中教授10人、研究员2人,副教授7人、副研究员1人、博士生导师7人,27人具有博士学位,具有层次高、国际化和年轻化的特点。
近几年,随着工程研究中心不断地建设与发展,在科技创新、产学研结合和人才培养方面取得了一系列可喜的成绩,为我区乃至全国多语言智能信息处理、大数据云计算服务提供了技术支撑。
paper 01
Alignment-Learning based single-step decoding for Accurate and fast Non-autoregressive Speech Recognition
作者:王勇和, 刘瑞, 飞龙,张晖,高光来
单位:内蒙古大学

本文提出一种基于对齐学习的非自回归Transformer(AL-NAT)语音识别方法。受端到端模型中编码器CTC的输出和目标序列具有单调相关性这一事实的启发。我们将编码器CTC的输出作为解码器的输入,并定义了一种对齐损失函数用于最小化该输入和目标序列之间的对齐成本矩阵。我们的方法不需要长度预测机制,在识别准确率和解码速度方面相比已有的NAT模型取得了显著提升。此外,为了学习上下文知识以提高识别准确率,我们进一步在编码器和解码器端分别增加了轻量级3-gram语言模型。实验结果表明,分别在编码器和解码器端增加语言模型对识别性能有很大提升。
A COMPLEX SPECTRAL MAPPING WITH INPLACE CONVOLUTION RECURRENT NEURAL NETWORKS FOR ACOUSTIC ECHO CANCELLATION
作者:张成刚, 刘晋江, 张学良
单位:内蒙古大学

近年来,深度学习技术被引入到声学回声消除(AEC)中,并取得了显著的效果。然而对于基于深度学习方法的AEC来说,最重要的问题是在多样性场景下模型的泛化能力。与大多数处理整个频段的方法不同,本文提出了用于端到端AEC的原地卷积递归神经网络(ICRN),它利用原地卷积和通道级的时间建模来确保近端信号信息得到保留。此外,本文采用复数频谱映射与多任务学习策略,获得更好的泛化能力。在多个不匹配的场景下进行的实验表明,所提出的方法优于以前的方法。
DRC-NET: DENSELY CONNECTED RECURRENT CONVOLUTIONAL NEURAL NETWORK FOR SPEECH DEREVERBERATION
作者:刘晋江, 张学良
单位:内蒙古大学
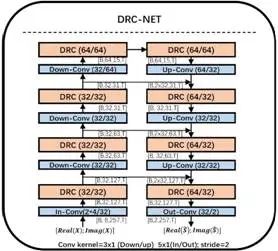

基于作者之前在时频域上使用Inplace CRN模型对每个频率点进行单独处理得到的显著性能提升。在本文中,该方法将单频点特征作为基本的处理单元,这使得模型可以统一RNN在时频域中对频率维度和时间维度的处理方式。在此基础上,该方法将卷积神经网络(CNN)和RNN紧密结合起来作为一种基本的时频域处理单元,最终得到了密连循环卷积神经网络(DRC-NET)。DRC-NET有效融合了RNN的无限冲击响应特性和CNN的有限冲击响应特性,使得性能得到了显著提升。实验结果表明,无论是非因果版本的DRC-NET还是因果版本的DRC-NET,语音去混响的性能都优于SOTA基线模型。
A ROBUST DEEP AUDIO SPLICING DETECTION METHOD VIA SINGULARITY DETECTION FEATURE
作者:张康豪1, 梁山2, 聂帅2,何树林1,潘家慧1,张学良1,马浩鑫2, 易江燕2
单位:1内蒙古大学, 2中国科学院自动化研究所

本文针对伪造语音中的半真半假音频鉴别提出了一种利用高频奇异性检测特征和序列信息进行音频鉴伪的方法,以弥补对于半真半假音频检测方法的缺失。给定当前待检测的音频,该方法首先对音频进行小波分解,并提取分解后的高频分量进行重构,提取出音频中的高频奇异点以及突变特征。然后利用长短时记忆模块(LSTM)进行序列建模,进行初步的奇异点上下文建模以及定位。为了消除音频本身存在的固有奇异点干扰,该方法组合了线性频率倒谱系数(LFCC)作为补充。该方法不仅实现了对于半真半假音频数据的鉴别,同时也对伪造的音频片段进行定位。所提方法为一种新型的攻击方式——半真半假音频提供了一种有效方法,且实验结果表明,相对于已有鉴伪方法,该方法在精度和鲁棒性方面都有了很大的提高。
Alleviating the Loss-Metric Mismatch in Supervised Single-Channel Speech Enhancement
作者:杨洋, 张晖, 张学良, 张怀文
单位:内蒙古大学
在本文中,作者研究了有监督的单通道语音增强系统的损失-度量不匹配问题。大多数现有的语音增强系统的性能并不令人满意,因为它们根据经验选择的损失函数与不可微的评估指标存在语义上的差距,又称损失-度量不匹配问题。在这项工作中,作者提出了一种简单而有效的方法,为真实的前端语音增强场景生成合适的损失函数,以缓解损失-度量不匹配的问题。具体来说,该方法采用了函数平滑技术,通过一组基函数及其线性组合来逼近不可微的评价指标。实验结果表明,由该方法生成的损失函数能够帮助语音增强系统在大多数评价指标上取得更显著的性能。
ATTENTION-BASED FUSION FOR BONE-CONDUCTED AND AIR-CONDUCTED SPEECH ENHANCEMENT IN THE COMPLEX DOMAIN
作者:王鹤鸣1, 张学良2, 汪德亮1
单位:1俄亥俄州立大学,2内蒙古大学

骨传导 (BC) 麦克风通过将人类头骨的振动转换为电信号来捕获语音信号。BC 传感器对噪声不敏感,但带宽有限。另一方面,传统或空气传导 (AC) 麦克风能够捕获全频带语音,但容易受到背景噪音。我们通过使用执行复杂频谱映射的卷积循环网络结合 AC 和 BC 麦克风的优势。为了更好地利用来自两种麦克风的信号,我们采用了基于注意力的融合以及早期融合和晚期融合策略。实验证明了所提出的方法优于其他最近结合 BC 和 AC 信号的语音增强方法。此外,我们的增强性能明显优于传统的语音增强对应物,尤其是在低信噪比场景中。


来源 :内蒙古大学新闻网
编辑 :崔睿韬
主编 :吴栓虎

关注公众号:拾黑(shiheibook)了解更多
友情链接:
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
安全、绿色软件下载就上极速下载站:https://www.yaorank.com/
找律师打官司就上碳链网:https://www.itanlian.com/






 内蒙古大学
内蒙古大学
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩



